学习Milvus数据库
Milvus 介绍
Milvus 是目前最受欢迎的开源向量数据库之一,专为存储与检索海量高维向量而设计。无论是文本语义搜索、以图搜图,还是多模态检索,Milvus 都能提供高性能、低延迟的检索能力。
1. 原理
Milvus 的核心目标是:
在海量高维向量集合中,以高性能、低延迟完成相似性搜索(Similarity Search)和向量检索(Vector Retrieval)。
基本原理:
- 向量化表示(Vectorization) 原始数据(文本、图像、音频、视频等)通过 Embedding 模型 转换为固定维度的浮点向量。
- 相似度计算
向量之间的相似度通常使用:
- 欧氏距离 (L2)
- 余弦相似度 (Cosine)
- 内积 (IP)
- 近似最近邻搜索(ANN) 通过 IVF、HNSW、DiskANN 等索引结构,在牺牲少量精度的情况下极大提升检索速度。
- 分布式存储与查询 通过 Sharding(分片)+ Replication(副本) 实现 PB 级数据存储与查询。
2. 架构
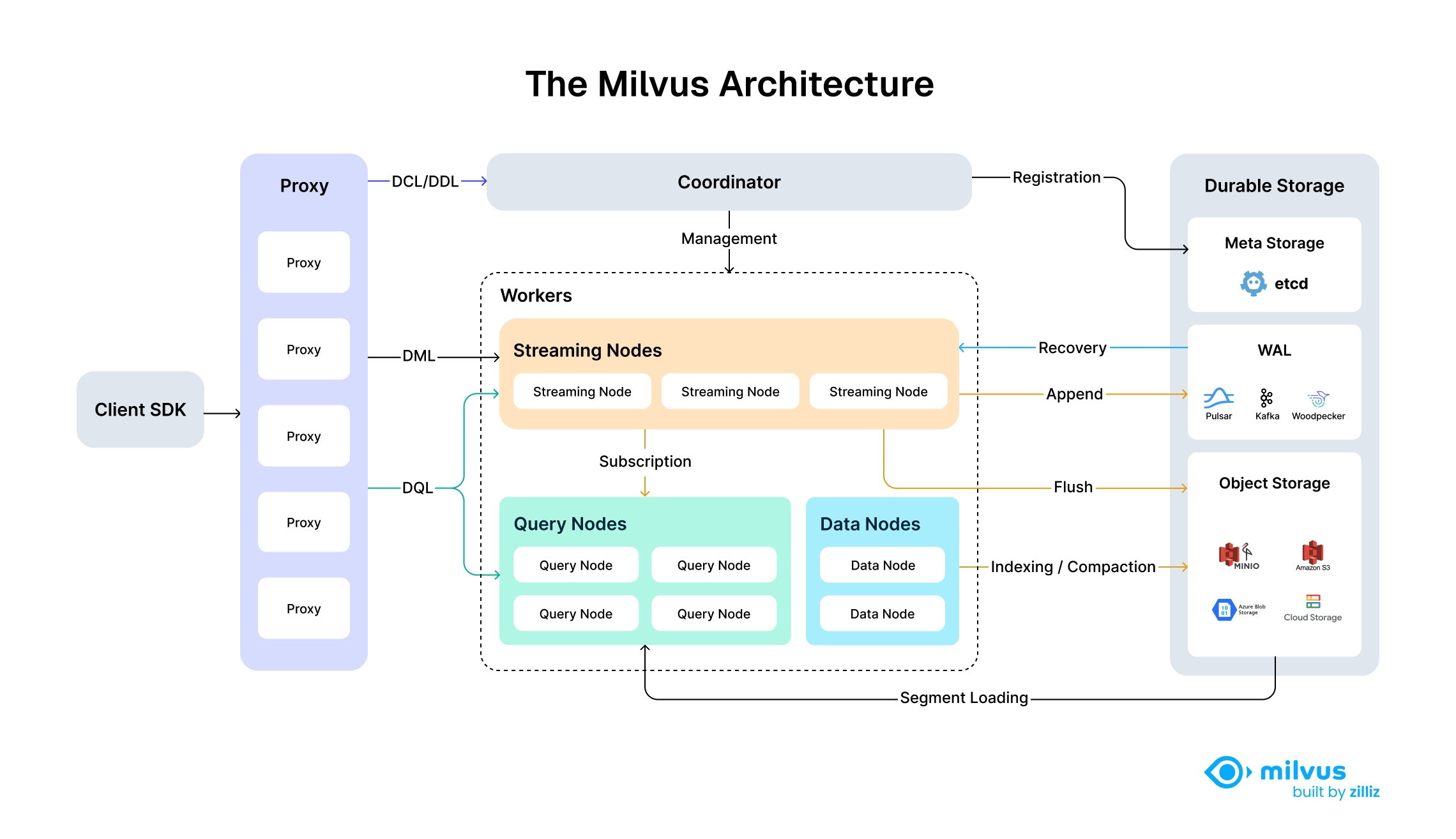
Milvus v2.x 的架构分为四层:
Access Layer
Coordinator Services
Worker Nodes
Storage Layer
-
Access Layer(访问层): 提供 gRPC / REST API,处理客户端请求、认证、负载均衡。
-
Coordinator Services(协调器):
- 接口介绍
- DCL/DDL:处理数据定义语言 (DDL) 和数据控制语言 (DCL) 请求,如创建或删除 Collections、分区或索引
- DML:数据操作,如插入、删除、更新数据
- DQL:数据查询
- 模块介绍
- RootCoord:管理集合、分区、元数据。
- QueryCoord:调度查询节点,分发搜索任务。
- DataCoord:管理数据写入、落盘、合并。
-
Worker Nodes(工作节点):
- StreamingNode: 流节点,提供一致性保证和故障恢复、增长数据查询和生成查询计划。
- QueryNode:执行向量检索。
- DataNode:处理数据插入与分片。
- IndexNode:构建 ANN 索引。
-
Storage Layer(存储):
- 元数据(etcd)
- 向量数据(MinIO / S3 / HDFS)
- 日志与消息队列(Pulsar / Kafka)
数据流和 API 类别
Milvus API 按其功能分类,并遵循架构的特定路径:
应用程序接口类别 操作符 示例应用程序接口 架构流程 DDL/DCL Schema 和访问控制 createCollection,dropCollection,hasCollection、createPartition访问层 → 协调器 DML 数据操作 insert,delete、upsert访问层 → 流工作节点 数据查询 数据查询 search,query访问层 → 批量工作节点(查询节点)
3. 关键词
| 关键词 | 说明 |
|---|---|
| Vector Embedding | 高维向量表示 |
| ANN | Approximate Nearest Neighbor |
| IVF | 倒排文件索引 |
| HNSW | 分层小世界图索引 |
| DiskANN | 磁盘型 ANN 索引 |
| Hybrid Search | 向量+结构化混合检索 |
| Sharding / Replication | 分片与副本 |
| Time Travel | 历史版本查询 |
| Load | 磁盘->内存 |
| Flush | 内存->磁盘 |
4. 使用示例
from pymilvus import connections, Collection, FieldSchema, CollectionSchema, DataType
import numpy as np
# 连接
connections.connect("default", host="localhost", port="19530")
# 定义 Schema
fields = [
FieldSchema(name="id", dtype=DataType.INT64, is_primary=True),
FieldSchema(name="embedding", dtype=DataType.FLOAT_VECTOR, dim=768)
]
schema = CollectionSchema(fields, description="Example collection")
collection = Collection(name="example", schema=schema)
# 插入数据
vectors = np.random.random((1000, 768)).astype(np.float32)
ids = list(range(1000))
collection.insert([ids, vectors])
collection.flush()
# 创建索引
collection.create_index(
field_name="embedding",
index_params={
"metric_type": "L2",
"index_type": "IVF_FLAT",
"params": {"nlist": 128}
}
)
collection.load()
# 搜索
query_vector = np.random.random((1, 768)).astype(np.float32)
results = collection.search(
query_vector,
"embedding",
param={"nprobe": 10},
limit=5
)
print(results)
5. 应用场景
| 场景 | 示例 |
|---|---|
| AI 语义搜索 | ChatGPT RAG 检索、知识库搜索 |
| 图像检索 | 电商商品相似图、以图搜图 |
| 视频检索 | 视频监控相似片段 |
| 音频检索 | 音乐识别、说话人检索 |
| 推荐系统 | 基于相似度的推荐 |
| 多模态搜索 | 图文混合搜索(CLIP Embedding) |
| 法律/医学检索 | 案例匹配、病历相似度分析 |
6. 索引选择
Milvus 支持多种索引,不同数据规模、延迟、内存要求下的推荐如下:
| 索引类型 | 特点 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| FLAT | 暴力搜索 | 精度 100% | 延迟高 | 小数据集 |
| IVF_FLAT | 倒排 + 全扫描 | 性能与精度平衡 | 精度略低 | 中等规模数据 |
| IVF_SQ8 | IVF + 8位量化 | 节省内存 | 精度下降 | 内存受限场景 |
| IVF_PQ | IVF + 产品量化 | 超低内存 | 精度下降大 | 亿级向量库 |
| HNSW | 小世界图 | 高精度、低延迟 | 内存大 | 延迟要求高 |
| DiskANN | 磁盘索引 | 支持超大数据 | 稍慢 | PB 级向量库 |
选择逻辑:
小数据(<100万) → 要高精度 → FLAT
→ 要快 → HNSW
中大数据(百万-亿级) → 内存够,延迟敏感 → HNSW
→ 内存有限 → IVF_PQ / IVF_SQ8
→ 平衡速度和精度 → IVF_FLAT
超大数据(>亿级) → 内存有限 → DiskANN
→ 内存充足、超高并发 → HNSW
7. 总结
Milvus 作为新一代向量数据库,通过分布式架构、灵活的索引类型以及多模态支持,为 AI 检索提供了高效的底层基础设施。 无论是搭建 RAG 系统,还是图像/视频/音频检索,Milvus 都能提供高性能 + 高扩展性的解决方案。 索引的选择需要结合数据规模、延迟、精度、内存资源综合评估,并建议通过实际测试找到最优配置。
